ユーザーの写真、曲、習慣を認識します。 人工知能ならそれはすでに可能です。 しかし、それはなぜ重要であり、私たちの生活にどのような影響を与えるのでしょうか?
この質問に答える前に、一歩下がって次の違いを説明する必要があります。 Artificial Intelligence (AI)、 機械学習 (ML) と 深層学習 (DL)、用語はよく混同されますが、非常に正確な意味を持っています。
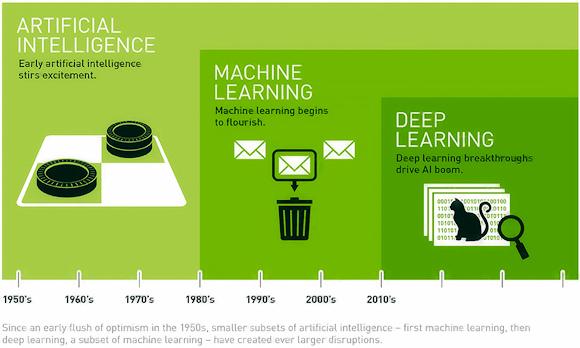
基本的な考え方を説明するために、NVIDIA サイトから取得した画像 (冒頭) を使用しましょう。
この画像から、AI の概念は ML の一般的な概念であり、ML は DL よりも一般的な概念であることが明らかです。 しかしそれだけではありません。 実際、最初のアルゴリズムを見ると、 深い学習 これらは、人間の知能の能力を模倣する目的で、LISP や PROLOG などの最初の言語を使用して 10 年代頃に誕生した人工知能とは異なり、わずか 50 年前に誕生しました。
最初の人工知能アルゴリズムは、(チェッカーやチェスのゲームのように) プログラマーによって定義された特定のロジックに従って特定の数のアクションを実行することに限定されていました。
スルー 機械学習、人工知能は、人工知能の「経験」を構成する大量の入力データに基づいて機械学習の数学的モデルを作成することを目的として、いわゆる教師ありおよび教師なし学習アルゴリズムを通じて進化してきました。
教師あり学習では、モデルを作成するために、各要素にラベルを割り当てて AI をトレーニングする必要があります。たとえば、果物を分類したい場合は、さまざまなリンゴの写真を撮り、梨、バナナなどの「リンゴ」というラベルをモデルに割り当てます。
教師なし学習では、プロセスが逆になります。さまざまな果物の画像からモデルを作成する必要があり、モデルは、リンゴ、梨、バナナに共通する特徴に従ってラベルを抽出する必要があります。
のモデル 機械学習 supervised はすでにウイルス対策やスパムフィルターで使用されていますが、Amazon が提案する製品などのマーケティングの分野でも使用されています。
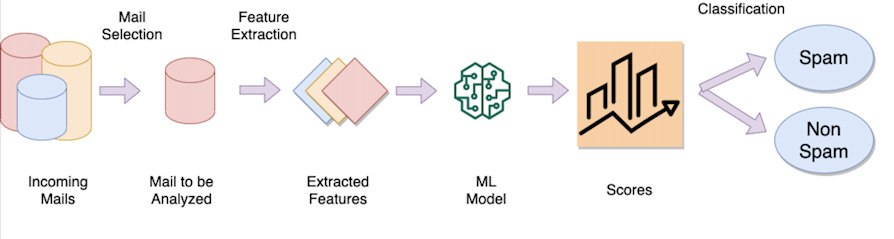
スパムフィルターの例
電子メール スパム フィルターの背後にある考え方は、数十万 (数百万ではないにしても) の電子メールから「学習」し、各電子メールに次のようなラベルを付けるモデルをトレーニングすることです。 スパム または合法です。 モデルがトレーニングされると、次のような分類操作が行われます。
テキストの単語、メールの送信者、送信元 IP アドレスなどの特有の特徴 (特徴と呼ばれる) の抽出。
抽出された各特徴の「重み」を考慮します (たとえば、テキスト内に 1000 個の単語がある場合、「バイアグラ」、「ポルノ」などの単語など、一部の単語は他の単語よりも識別力が高い可能性があります。それらは、おはよう、大学などとは異なる重みを持ちます)。
特徴 (単語、送信者など) とそれぞれの重みを入力として受け取り、数値を返す数学関数を実行します。
この値が特定のしきい値を上回っているか下回っているかを確認して、電子メールが正当なものであるか、スパム (分類) とみなすべきかを判断します。
人工ニューロン
言われたように、 深い学習 の支店です 機械学習。 との違い 機械学習 それは、人工ニューラル ネットワークで構成される「階層化された」学習構造を使用して大量のデータを実行する計算の複雑さです。 この概念を理解するには、以下の図のように単一の人間のニューロンを複製するという考えから始めます。
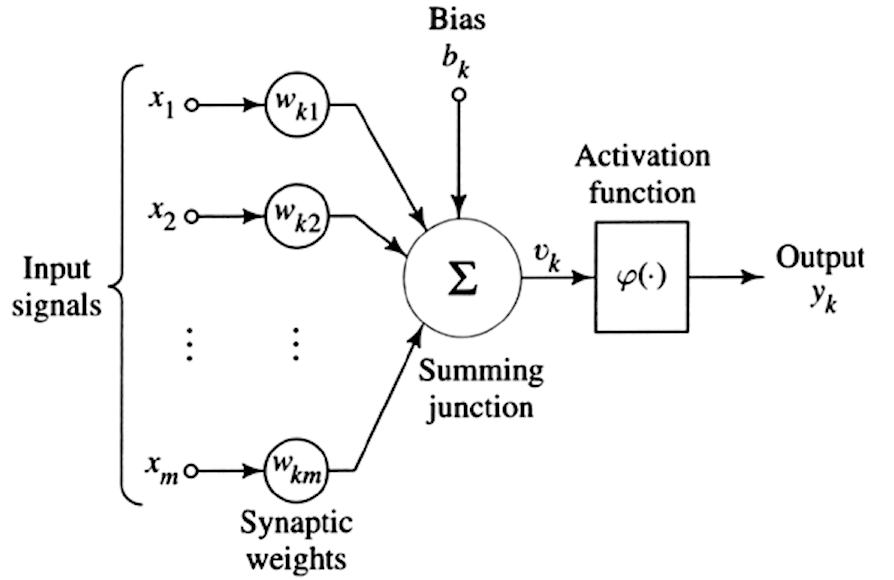
機械学習で前に示したように、一連の入力信号 (画像の左側) にさまざまな重み (Wk) を関連付け、認知的な「バイアス」 (bk)、つまり一種の歪みを追加し、最後に活性化関数、つまりシグモイド関数、双曲線正接、ReLU などの数学関数を適用します。 これは、一連の重み付けされた入力を受け取り、バイアスを考慮して、出力 (yk) を返します。
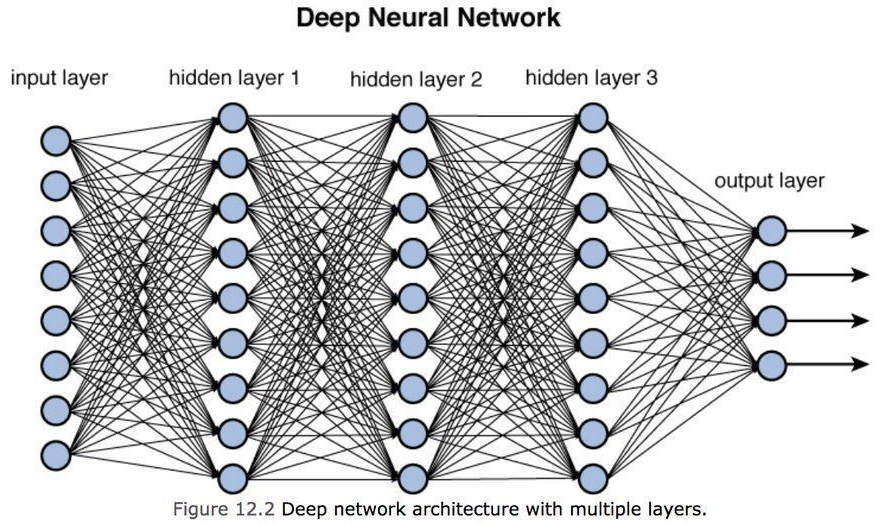
これは単一の人工ニューロンです。 ニューラル ネットワークを作成するには、単一のニューロンの出力が次のニューロンの入力の XNUMX つに接続され、実際のネットワークを表す下の図に示すような密な接続ネットワークが形成されます。 ディープニューラルネットワーク.
ディープラーニング
上の図からわかるように、ニューラル ネットワークに提供する一連の入力 (入力層)、次にモデルの「層」を表す隠れ層と呼ばれる中間層、そして最後に、あるオブジェクトを別のオブジェクトに対して区別 (または認識) できる出力層があります。 各隠れ層を学習能力として考えることができます。中間層の数が多いほど (つまり、モデルが深いほど)、理解はより正確になりますが、実行される計算もより複雑になります。
出力層は、ある程度の確率で出力値のセットを表すことに注意してください。たとえば、95% がリンゴ、4,9% が梨、0,1% がバナナなどです。
の分野での DL モデルを想像してみましょう。 コンピュータビジョン: 最初のレイヤーはオブジェクトのエッジを認識でき、エッジから始まる XNUMX 番目のレイヤーは形状を認識でき、形状から始まる XNUMX 番目のレイヤーは複数の形状で構成される複雑なオブジェクトを認識でき、複雑な形状から始まる XNUMX 番目のレイヤーは詳細を認識できます。 モデルを定義する際に、正確な数はありません。 隠れ層ただし、制限は、一定の時間内にモデルをトレーニングするために必要な電力によって課されます。
あまり詳細には立ち入りませんが、ニューラル ネットワークのトレーニングの目的は、モデル内に存在するすべての個々のニューロンに適用されるすべての重みとバイアスを計算することです。したがって、中間層 (隠れ層) が増加するにつれて、複雑さが指数関数的に増加することは明らかです。 このため、グラフィックス カード プロセッサ (GPU) が長年使用されてきました。 トレーニング: これらのカードは、CPU とは異なり、SIMD (単一命令複数データ) アーキテクチャおよび i テンソルコア これにより、ハードウェアでの配列操作が可能になります。
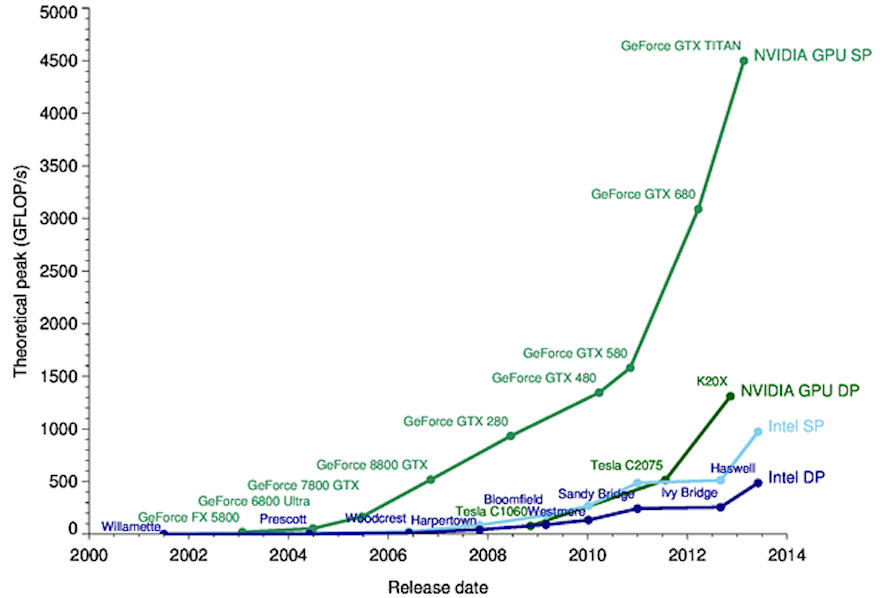
深層学習アプリケーション
これらのモデルは、膨大な量のデータを処理することにより、データが不完全または不正確であっても、障害やノイズに対する高い耐性を備えています。 したがって、それらは現在、科学のあらゆる分野で基本的なサポートを提供しています。 いくつか見てみましょう。
画像の分類とセキュリティ
犯罪が発生した場合、監視カメラで撮影した画像から顔の認識を開始し、数百万の顔のデータベースと比較することができます。この操作を人間が手動で行う場合、数か月、場合によっては数年かかる可能性があります。 さらに、一部のモデルでは、画像の再構築により、元の色の 100% に近い精度で画像の欠落部分に色を付けることができます。
自然言語処理
人間と同じように書き言葉や話し言葉を理解するコンピューターの能力。 最も有名なシステムの XNUMX つである Alexa と Siri は、異なる性質の質問を理解するだけでなく、答えることもできます。
他のモデルでもできること 感情分析、常にテキストまたは単語から抽出システムと意見を使用します。
医学的診断
医療分野では、これらのモデルは現在、CT スキャンや MRI の分析などの診断を行うために使用されています。 出力層で 90 ~ 95% の信頼度を持つ結果は、場合によっては人間の介入なしで患者の治療を予測できます。 毎日 24 時間勤務できるため、患者のトリアージ段階でもサポートを提供でき、救急部門での待ち時間が大幅に短縮されます。
自動運転
自動運転システムには継続的なリアルタイム監視が必要です。 より高度なモデルでは、乗客の存在のみを想定し、乗車が予測されていないドライバーとは独立して、あらゆる運転状況を管理できる車両が想定されています。
予測とプロファイリング
金融ディープラーニング モデルを使用すると、将来の市場動向について仮説を立てたり、金融機関の倒産のリスクを人間がインタビュー、研究、アンケート、手作業で計算することよりも正確に知ることができます。
これらのモデルをマーケティングに活用することで、例えば、同じような購買履歴を持つ他のユーザーとの関連付けに基づいて、人々の好みを知り、新商品を提案することが可能になります。
適応進化
ロードされた「エクスペリエンス」に基づいて、モデルは環境内で発生する状況、またはユーザー入力によって発生する状況に適応できます。 適応アルゴリズムにより、モデルとの新しい相互作用に基づいてニューラル ネットワーク全体が更新されます。 たとえば、YouTube が私たちの新しい個人的な好みや興味に合わせて、毎日、毎月、期間に応じて特定のテーマのビデオをどのように提供しているかを想像してみましょう。
最後に、 深層学習 それは依然として強力に拡大している研究分野です。 大学でも、依然として数学のしっかりした基礎が必要なこの主題に関する教育プログラムを更新しています。
DL を産業、研究、健康、日常生活に適用することで得られる利点は疑いの余地がありません。
しかし、これは人間にサポートを提供するものでなければならず、限られた非常に特殊な場合にのみ人間に取って代わることができることを忘れてはなりません。 実際、現在まで、あらゆるタイプの問題を解決できる「汎用」モデルは存在しません。
もう XNUMX つの側面は、これらのテンプレートをビデオの作成などの違法な目的で使用することです。 ディープフェイク (記事を参照)、つまり、フェイク ニュース、詐欺、またはリベンジ ポルノを作成する目的で、元の画像やビデオに他の画像やビデオを重ねるために使用される技術です。
これらのモデルを使用するもう XNUMX つの違法な方法は、敵対的機械学習など、コンピューター システムを侵害することを目的とした一連の手法を作成することです。 このような手法により、モデルを誤って分類したり (したがって、モデルに誤った選択をさせる)、使用されたデータセットに関する情報を取得したり (プライバシーの問題を引き起こしたり)、モデルのクローンを作成したり (著作権の問題を引き起こしたり) する可能性があります。
リファレンス
https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-int...
https://it.wikipedia.org/wiki/Lisp
https://it.wikipedia.org/wiki/Prolog
https://it.wikipedia.org/wiki/Apprendimento_supervisionato
https://www.enjoyalgorithms.com/blog/email-spam-and-non-spam-filtering-u...
https://foresta.sisef.org/contents/?id=efor0349-0030098
https://towardsdatascience.com/training-deep-neural-networks-9fdb1964b964
https://hemprasad.wordpress.com/2013/07/18/cpu-vs-gpu-performance/
https://it.wikipedia.org/wiki/Analisi_del_sentiment
https://www.ai4business.it/intelligenza-artificiale/auto-a-guida-autonom...
https://www.linkedin.com/posts/andrea-piras-3a40554b_deepfake-leonardodi...










